انجام پروژههای یادگیری عمیق همواره فرایندی زمانبر و پرهزینه بوده که به منابع رایانشی و دادههای آموزش عظیمی نیاز دارد. اما روشی به نام یادگیری انتقالی یا Transfer Learning به عنوان راهکار میانبر در این زمینه مطرح است.
آیتیمن-امروزه برنامههای هوش مصنوعی، قادر به بازشناسی چهره و اشیای درون عکس و ویدیو، تشخیص بی درنگ متن موسیقی، تشخیص پیش از موعد سرطان از روی تصاویر رادیوگرافی و پیروزی بر انسان در بازیهای پیچیده فکری هستند.
تا همین چند سال پیش، تمامی اینها یا نشدنی مینمود یا به نظر میرسید رسیدن به این سطح از پیشرفت، به دههها زمان نیاز دارد. اما پیشرفت در فناوریهایی مانند شبکههای عصبی (Neural Networks) و یادگیری عمیق (Deep Learning)، شاخهای از هوش مصنوعی که در سالهای اخیر به محبوبیت ویژهای دست یافته، کمک کرد که کامپیوترها، این چالشها را پشت سر بگذارند و علاوه بر این، بسیاری مسایل پیچیده دیگر را نیز حل کنند.
اما مدلهای یادگیری عمیق نیازمند دسترسی به حجم عظیمی از داده و منابع رایانشی هستند که این منابع برای همه در دسترس نیست. از سوی دیگر، فرایند یادگیری مدلهای یادگیری عمیق به منظور انجام وظایف، زمانبر است و این مساله، کاربری آنها را در مواردی که زمان محدود باشد، دشوار میکند.
اما خوشبختانه برای حل این مساله، راهکاری به نام یادگیری انتقالی (transfer learning) وجود دارد؛ راهکاری که در آن، دانش به دست آمده در یک مدل هوش مصنوعی، به مدل دیگر منتقل میشود.
هزینه آموزش مدلهای یادگیری عمیق
یادگیری عمیق زیرمجموعهای از یادگیری ماشین است که یادگیری ماشین خود، علم توسعه هوش مصنوعی از طریق دادههای آموزش است. ایده و دانش پشت یادگیری عمیق و شبکههای عصبی به اندازه خود هوش مصنوعی عمر دارد. اما تا همین اواخر، جامعه هوش مصنوعی آنها را ناکارآمد میدانست. اما در چند سال گذشته، با در دسترس قرار گرفتن دادهها در مقیاس کلان و منابع رایانشی، شبکههای عصبی در صدر توجهات قرار گرفت و طراحی الگوریتمهای یادگیری عمیق برای حل مشکلات واقعی جهان، میسر شد.
برای آموزش یک مدل یادگیری عمیق، معمولا باید نمونههای تفسیرشده متعددی را در وارد یک شبکه عصبی کرد. این نمونهها میتوانند چیزهایی مانند تصاویر برچسب گذاری شده از اشیا یا اسکن ماموگرافی بیماران به همراه نتیجههای محتمل آنها باشد. شبکه عصبی این تصاویر را تحلیل و مقایسه میکند و مدلهای ریاضی میسازد که نمایانگر الگوهای تکراری بین تصاویر یک دستهبندی مشابه است.
هم اکنون مجموعه دادههای عظیم و منبع باز متعددی وجود دارد؛ برای مثال ImageNet پایگاه دادهای مشتمل بر حدود 14 میلیون تصویر برچسب گذاری شده در 22 هزار دستهبندی مختلف است. یا MNIST که مجموعه دادهای از 60 هزار عدد نوشته شده با دستخطهای مختلف را در خود دارد و مهندسان هوش مصنوعی میتوانند از این منابع برای آموزش مدلهای یادگیری عمیق خود استفاده کنند.
اما علاوه بر دادهها، آموزش مدلهای یادگیری عمیق به منابع رایانشی قدرتمند نیز وابسته است. توسعه دهندگان معمولا از خوشه (کلاستر)هایی از پردازشگر، پردازشگر گرافیکی یا سخت افزارهای ویژهای مانند پردازشگرهای تنسور (Tensor) گوگل (TPU) برای آموزش شبکههای عصبی در مدت زمان بهینه استفاده میکنند.
هزینه خریداری یا اجاره چنین منابعی اما میتواند از بودجه توسعهدهندگان منفرد یا سازمانهای کوچک بالاتر بزند. از سوی دیگر، برای بسیاری از مسایل، نمونههای لازم و کافی برای آموزش مدلهای پیشرفته هوش مصنوعی وجود ندارد.
یادگیری انتقالی وارد میشود
اگر یک مهندس هوش مصنوعی بخواهد یک شبکه عصبی طبقهبندی تصاویر برای حل یک مساله مشخص بسازد، میتواند به جای گردآوری هزاران و میلیونها تصویر، از یکی از مجموعهدادههای موجود مانند ImageNet استفاده و آن را با عکسهایی از یک دامنه خاص تقویت کند. اما وی همچنان باید هزینهای گزاف را صرف خرید یا اجاره منابع رایانشی لازم برای پردازش میلیونها تصویر در شبکه عصبی بکند.
اینجاست که یادگیری انتقالی وارد میشود.
یادگیری انتقالی، پروسه ایجاد مدلهای جدید هوش مصنوعی از طریق تنظیم شبکههای عصبیای است که قبلا آموزش داده شدهاند.
به این ترتیب، توسعه دهندگان بهجای آموزش دادن شبکههای عصبی از نقطه صفر، میتوانند یک مدل یادگیری عمیق منبع باز و پیش آموخته (Pretrained) را دانلود و آن را برای هدف خود تنظیم کنند.
هم اکنون مدلهای پایهای پیش آموخته متعددی وجود دارد که میتوان از آنها استفاده کرد. نمونههای محبوب و شناخته شده آن شامل AlexNet، Inception-v3 و ResNet میشود. این شبکههای عصبی روی مجموعهدادههای ImageNet آموزش داده شدهاند و مهندسان هوش مصنوعی کافی است که آنها را با انجام آموزشهای تکمیلی با نمونههای خاص خود، تقویت کنند.
یادگیری انتقالی از این طریق، دادههای مورد نیازش را تامین میکند و از سوی دیگر، نیاز به منابع رایانشی گرانقیمت هم ندارد و در بسیاری موارد، یک کامپیوتر رومیزی یا لپتاپ قوی، برای بهینهسازی و تنظیم شبکههای عصبی پیش آموخته، و صرف چند ساعت زمان به این منظور کفایت میکند.
یادگیری انتقالی چگونه کار میکند؟
شبکه های عصبی رفتار خود را به روش سلسله مراتبی توسعه میدهند. هر شبکه عصبی از چند لایه تشکیل شده است که پس از آموزش، هر یک از لایهها برای شناسایی ویژگیهای خاص در دادههای ورودی تنظیم میشوند.
برای مثال در یک شبکه عصبی پیچشی (convolutional neural network) طبقهبندی تصویر، چند لایه اول به بازشناسی جنبههای عمومی مانند لبهها و گوشهها، دوایر، لکههای رنگ اختصاص دارد و به لایههای عمیقتر شبکه عصبی که برویم، مواردی همچون بازشناسی چیزهایی پیچیدهتر، مانند چشمها، چهره و کل یک شیء انجام میشود.
مهندسان هوش مصنوعی از طریق یادگیری انتقالی، در واقع لایههای بالاتر شبکههای عصبی پیش آموخته را حفظ یا freeze میکنند؛ زیرا بازشناسی جنبههای عمومی در تمامی حوزهها مشترک است. آنان سپس باید لایههای پایینتر را با نمونههای مورد نظر خود آموزش بدهند و تنظیم بکنند و لایههای جدیدی را برای طبقهبندی دستههای تازهای که مجموعه دادههای آموزش آنها را شامل میشود، به شبکه عصبی بیفزایند.
به این مدلهای هوش مصنوعی پیش آموخته و مدلهای تقویت شده به ترتیب معلم و دانش آموز هم میگویند.
تعداد لایههای حفظ شده و تقویت شده، بسته به مشابهتها بین منبع و هدف در مدلهای هوش مصنوعی متفاوت است. اگر یک مدل هوش مصنوعی دانش آموز مسالهای مشابه معلم را حل کند، نیازی به تقویت و تنظیم لایههای مدل پیش آموخته وجود ندارد و توسعه دهنده کافی است که لایههای جدیدی را به انتهای شبکه عصبی اضافه کند و آنها را با دستهبندیهای جدید آموزش دهد. به این فرایند deep-layer feature extraction میگویند. این فرایند وقتی دادههای آموزش اندکی برای حوزه مقصد وجود دارد نیز مورد استفاده قرار میگیرد.
اما وقتی تفاوت قابل توجهی بین منبع و مدل مقصد وجود داشته باشد یا نمونههای آموزش فراوان باشد، توسعه دهندگان لایههای متعددی از مدل هوش مصنوعی پیش آموخته را باز یا به اصطلاح Unfreeze میکنند و لایههای طبقهبندی جدیدی را به منظور تقویت این لایهها با نمونههای جدید اضافه میکنند. به این فرایند نیز mid-layer feature extraction گفته میشود.
در مواردی هم که تفاوت بین منبع و مدل هوش مصنوعی هدف خیلی زیاد باشد، توسعه دهندگان کل لایههای شبکه عصبی را باز میکنند و آن را از نو آموزش میدهند که به آن تنظیم کل مدل (full model fine-tuning) گفته میشود. این نوع از یادگیری انتقالی نیز نیازمند نمونههای آموزش بسیار است.
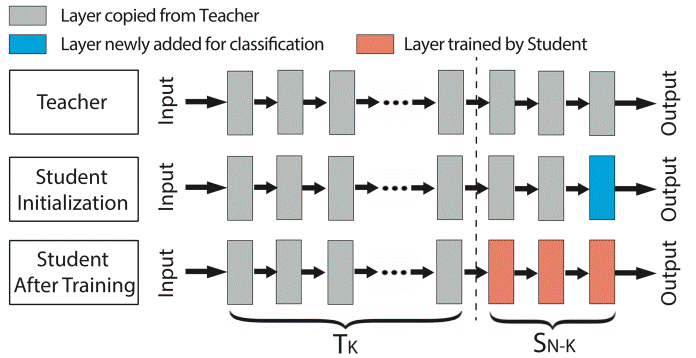
شاید گرفتن یک مدل پیش آموخته و بازآموزی تمامی لایههای آن، به نظر مضحک برسد. اما در عمل، این کار موجب صرفهجویی قابل توجهی در زمان و منابع رایانشی میشود.
پیش از آموزش، متغیرهای یک شبکه عصبی با اعداد تصادفی تنظیم میشود در سپس این متغیرها در فرایند آموزش تطبیق داده میشوند. مقادی این متغیرها در یک شبکه عصبی پیش آموخته، با میلیونها نمونه آموزش تنظیم شده است. بنابراین، این مقادیر برای نقطه شروع یک مدل هوش مصنوعی جدید بهتر هستند و با نمونههای بسیار کمتری میتوان آنها را برای مدل مورد نظر، بهینه کرد.
یادگیری انتقالی، کلید همه مشکلات نیست
یادگیری انتقالی بسیاری از مشکلات آموزش مدلهای هوش مصنوعی را به روشی کارآمد و مقرون به صرفه برطرف میکند. با این حال نقاط ضعفی هم دارد. مثلا اگر یک شبکه عصبی پیش آموخته دارای حفرههای امنیتی باشد، مدلهای هوش مصنوعی که از آن به عنوان پایه استفاده میکنند ، آن آسیب پذیریها را به ارث میبرند.
همچنین در برخی حوزههای مانند آموزش هوش مصنوعی برای انجام بازیها، استفاده از یادگیری انتقالی خیلی محدود است. این مدلهای هوش مصنوعی به روش یادگیری تقویتی (reinforcement learning) آموزش داده میشوند. یادگیری تقویتی شاخهای از هوش مصنوعی است که بر رفتارهایی تمرکز دارد که ماشین باید برای بیشینه کردن پاداشش انجام دهد و بسیار وابسته به تکرار و سعی و خطاست. در یادگیری تقویتی عمدتا مسایل جدید هستند و نیازمند مدل هوش مصنوعی و پروسه آموزش ویژه خود هستند.
اما در کل، برای بسیاری از کاربردهای یادگیری عمیق، مانند طبقهبندی تصاویر و پردازش زبان طبیعی، امکان اینکه بتوان از طریق یادگیری انتقالی، مسیر میانبر را طی کرد، وجود دارد.
 دریافت لینک صفحه با کد QR
دریافت لینک صفحه با کد QR